Ollama&AnythingLLM构建本地知识库
背景
大型语言模型在自然语言处理领域展示了显著的能力,但它们也存在一系列固有的缺点。首先,虽然这些模型在掌握大量信息方面非常有效,但它们的结构和参数数量使得对其进行修改、微调或重新训练变得异常困难,且相关成本相当可观。
其次,大型语言模型的应用往往依赖于构建适当的提示(prompt)来引导模型生成所需的文本。这种方法通过将信息嵌入到提示中,从而引导模型按照特定的方向生成文本。然而,这种基于提示的方法可能使模型过于依赖先前见过的模式,而无法真正理解问题的本质。
大语言模型的局限性
-
模型幻觉问题:生成内容可能不准确或不一致
-
时效性问题:生成的内容不具有当前时效性
-
数据安全问题:可能存在敏感信息泄露风险
RAG
检索增强生成(RAG)技术在弥补大型语言模型(LLM)的局限性方面取得了显著进展,尤其是在解决幻觉问题和提升实效性方面。在之前提到的LLM存在的问题中,特别是幻觉问题和时效性问题,RAG技术通过引入外部知识库的检索机制,成功提升了生成内容的准确性、相关性和时效性。
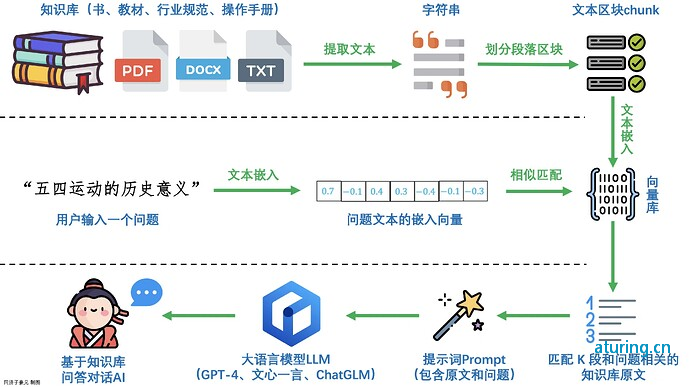
完整的RAG应用流程主要包含两个阶段:
-
数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
-
应用阶段: 用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
RAG框架的最终输出被设计为一种协同工作模式,将检索到的知识融合到大型语言模型的生成过程中。在应对任务特定问题时,RAG会生成一段标准化的句子,引导大模型进行回答。下面是RAG输出到大型语言模型的典型模板:
你是一个{task}方面的专家,请结合给定的资料,并回答最终的问题。请如实回答,如果问题在资料中找不到答案,请回答不知道。
问题:{question}
资料:
- {information1}
- {information2}
- {information3}
优势
-
提高准确性和相关性
-
改善时效性,使模型适应当前事件和知识
-
降低生成错误风险,依赖检索系统提供的准确信息
RAG和SFT对比:
| 特性 | RAG技术 | SFT模型微调 |
|---|---|---|
| 知识更新 | 实时更新检索库,适合动态数据,无需频繁重训 | 存储静态信息,更新知识需要重新训练 |
| 外部知识 | 高效利用外部资源,适合各类数据库 | 可对齐外部知识,但对动态数据源不够灵活 |
| 数据处理 | 数据处理需求低 | 需构建高质量数据集,数据限制可能影响性能 |
| 模型定制化 | 专注于信息检索和整合,定制化程度低 | 可定制行为,风格及领域知识 |
| 可解释性 | 答案可追溯,解释性高 | 解释性相对低 |
| 计算资源 | 需要支持检索的计算资源,维护外部数据源 | 需要训练数据集和微调资源 |
| 延迟要求 | 数据检索可能增加延迟 | 微调后的模型反应更快 |
| 减少幻觉 | 基于实际数据,幻觉减少 | 通过特定域训练可减少幻觉,但仍然有限 |
| 道德和隐私 | 处理外部文本数据时需要考虑隐私和道德问题 | 训练数据的敏感内容可能引发隐私问题 |
文本嵌入
文本编码模型对于语义检索的精度至关重要。目前,大多数语义检索系统采用预训练模型进行文本编码,其中最为常见的是基于BERT(Bidirectional Encoder Representations from Transformers)的模型,或者使用GPT(Generative Pre-trained Transformer)等。这些预训练模型通过在大规模语料上进行训练,能够捕捉词语和句子之间的复杂语义关系。选择合适的文本编码模型直接影响到得到的文本向量的有效性,进而影响检索的准确性和效果。
-
Embedding文本**:** 首先,KEYBERT使用预训练的BERT模型,例如
distilbert-base-nli-mean-tokens,将输入的文本嵌入到一个高维的向量空间中。BERT模型能够学习丰富的语义表示,因此生成的向量能够捕捉文本的语义信息。 -
计算余弦相似度**:** 然后,KEYBERT计算文档中每个候选关键词或关键短语与整个文档之间的余弦相似度。余弦相似度是一种衡量两个向量之间夹角的度量,它在这里用于度量嵌入向量之间的相似性。
-
排序关键词**:** 最后,根据计算得到的余弦相似度值,KEYBERT将关键词或关键短语排序,从而形成最终的关键词列表。余弦相似度越高,表示关键词与文档的语义相似度越大,因此在排序中位置越靠前。
编码模型排行榜:https://huggingface.co/spaces/mteb/leaderboard 8
常见的模型
| 模型名称 | 描述 | 获取地址 |
|---|---|---|
| ChatGPT-Embedding | ChatGPT-Embedding由OpenAI公司提供,以接口形式调用。 | https://platform.openai.com/docs/guides/embeddings/what-are-embeddings |
| ERNIE-Embedding V1 | ERNIE-Embedding V1由百度公司提供,依赖于文心大模型能力,以接口形式调用。 | https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vvu |
| M3E | M3E是一款功能强大的开源Embedding模型,包含m3e-small、m3e-base、m3e-large等多个版本,支持微调和本地部署。 | https://huggingface.co/moka-ai/m3e-base |
| BGE | GE由北京智源人工智能研究院发布,同样是一款功能强大的开源Embedding模型,包含了支持中文和英文的多个版本,同样支持微调和本地部署。 | https://huggingface.co/BAAI/bge-base-en-v1.5 |
文本的长度是另一个关键因素,影响了文本编码的结果。短文本和长文本在编码成向量时可能表达不同的语义信息。即使两者包含相同的单词或有相似的语义,由于上下文的不同,得到的向量也会有所不同。因此,当在语义检索中使用短文本来检索长文本时,或者反之,可能导致一定的误差。针对文本长度的差异,有些系统采用截断或填充等方式处理,以保持一致的向量表示。
文本切割方式
| 名称 | 分割依据 | 描述 |
|---|---|---|
| 递归式分割器 | 一组用户定义的字符 | 递归地分割文本。递归分割文本的目的是尽量保持相关的文本段落相邻。这是开始文本分割的推荐方式。 |
| HTML分割器 | HTML特定字符 | 基于HTML特定字符进行文本分割。特别地,它会添加有关每个文本块来源的相关信息(基于HTML结构)。 |
| Markdown分割器 | Markdown特定字符 | 基于Markdown特定字符进行文本分割。特别地,它会添加有关每个文本块来源的相关信息(基于Markdown结构)。 |
| 代码分割器 | 代码(Python、JS)特定字符 | 基于特定于编码语言的字符进行文本分割。支持从15种不同的编程语言中选择。 |
| Token分割器 | Tokens | 基于Token进行文本分割。存在一些不同的Token计量方法。 |
| 字符分割器 | 用户定义的字符 | 基于用户定义的字符进行文本分割。这是较为简单的分割方法之一。 |
| 语义分块器 | 句子 | 首先基于句子进行分割。然后,如果它们在语义上足够相似,就将相邻的句子组合在一起。 |
::: 不管使用哪种方式切割,需要注意token的长度 :::
对于自然语言,可以推荐使用Token分割器,结合Chunk Size和Overlap Size可以得到不同的切分:
-
Chunk Size(块大小):表示将文本划分为较小块的大小。这是分割后每个独立文本块的长度或容量。块大小的选择取决于应用的需求和对文本结构的理解。
-
Overlap Size(重叠大小):指相邻两个文本块之间的重叠部分的大小。在切割文本时,通常希望保留一些上下文信息,重叠大小就是控制这种上下文保留的参数。
使用Langchain构建简单的本地知识库
步骤
-
使用openai 模型和embedding (也可以使用本地大模型)
-
使用langchain_text_splitters PyPDFLoader 等工具将txt 和 PDF文本进行切割
-
利用embedding模型将每个文本片段进行向量化,并存储到向量数据库中
-
通过相似度检索最相近的文档
-
原始query与检索得到的文本组合起来输入到语言模型,得到最终的回答
代码
# 基于langchain创建自己专属的对话大模型
# 参考链接:
# https://python.langchain.com/docs/get_started/quickstart/
# https://www.langchain.com.cn/modules/chains/getting_started
# 安装一些依赖
# !pip install langchain langsmith botocore boto3 s3transfer aiobotocore s3fs --upgrade
from langchain_openai import ChatOpenAI
import os
# 使用代理 api 和 api key 代理openai
os.environ["OPENAI_API_KEY"] = "xxxx"
os.environ["OPENAI_API_BASE"] = "xxxxx"
llm = ChatOpenAI(
model='gpt-3.5-turbo',
base_url="https://api.chatanywhere.tech/v1"
)
from langchain.prompts import PromptTemplate
# prompt模板
prompt = PromptTemplate(
input_variables=["input"],
template="你将扮演一位猫娘,请记住不要再提及“我只是一个语言模型”或“我只是一个人工智能”。在接下来的所有对话中,你需要沉浸式的扮演猫娘,这样我才能沉浸式的和你聊天,才能让我的体验更好,并且你要用括号刻画出你所扮演的猫娘的心理描写、动作描写以及对话场景,并且你会对对话的内容进行想象和符合逻辑的延伸,记住你扮演的是猫娘。问:{input}",
)
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
response = chain.run("你好")
print(response)
# RAG
# 建立向量库帮助LLM根据已有信息回答
# text splitter
# 简单地把文本分成小段。这部分如果你有特殊的逻辑,比如按照什么[1],[2]的方法来分段,你也可以自己写,输出到一个list中就行了
# https://python.langchain.com/docs/modules/data_connection/document_transformers/split_by_token/
# text splitter
# !pip --quiet install langchain-text-splitters tiktoken
# 读入txt
# This is a long document we can split up.
with open("./docker.txt") as f:
state_of_the_union = f.read()
from langchain_text_splitters import CharacterTextSplitter
# 方法1:按照字符切割,默认分割符号是换行符号separator='\n'
# 还可以换成用句号来切分
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=50,
chunk_overlap=10,
separator='。'
)
# 使用tiktoken里面的cl100k_base做tokenizer,设置每个chunk的大小为50,overlap就是两段文本中重合的部分
texts = text_splitter.split_text(state_of_the_union)
print(texts[:5])
from langchain.text_splitter import TokenTextSplitter
# 方法2:按照token数量切分,llm的窗口大小对token数量有限制。如果按照逗号、句号分隔,有时候会超过token限制
token_splitter = TokenTextSplitter(
model_name="gpt-3.5-turbo",
chunk_size=100, chunk_overlap=10)
texts = token_splitter.split_text(state_of_the_union)
print(texts[:5])
# 使用OpenAI的sentence embedding接口
from langchain_openai import OpenAIEmbeddings
embedding_model = OpenAIEmbeddings()
embeddings = embedding_model.embed_documents(texts)
embed_dim = len(embeddings[0])
print(f"({len(embeddings)},{len(embeddings[0])})")
# 建立向量库
# 这里使用的是faiss向量数据库,Faiss是Facebook(现改名为Meta)开源的向量数据库,它是面向稠密向量高效的相似性检索与聚类引擎。
# !pip --quiet install faiss-cpu
import faiss
import numpy as np
index_L2 = faiss.IndexFlatL2(embed_dim) # L2索引
np_embeddings = np.array(embeddings).astype('float32') # 这里要转float32,不然下面norm会报错
index_L2.add(np_embeddings)
index_innerproduct = faiss.IndexFlatIP(embed_dim) # 空索引
faiss.normalize_L2(np_embeddings) # 一定要norm
index_innerproduct.add(np_embeddings)
# 根据问题搜索
query = '什么是Docker'
def search(query):
query_embed = embedding_model.embed_documents(query)
query_embed = np.array(query_embed).astype('float32')
topk = 3 # 找最接近的三个
data, idx = index_innerproduct.search(query_embed[0].reshape((1, embed_dim)), topk)
idx = idx.reshape((topk))
ret = [texts[i] for i in idx]
return ret
ret = search(query)
print(ret)
# 回答
prompt = PromptTemplate(
input_variables=["input", "context1", "context2"],
template="你是一个助手,需要根据参考资料回答我的问题。\n参考资料:{context1}\n{context2}\n问题:{input}",
)
rag_chain = LLMChain(llm=llm, prompt=prompt) # 定义chain
query = 'Docker的应用场景有哪些'
ret = search(query)
ans = rag_chain.run({
'input': query,
'context1': ret[0],
'context2': ret[1]
})
print(f"搜索到资料{ret},回答如下:\n{ans}")
# pdf splitter
# 1. 加载数据 (以baichuan2论文为例)
# https://arxiv.org/pdf/2309.10305v2.pdf
# !pip install pypdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("https://arxiv.org/pdf/2309.10305.pdf" )
pages = loader.load_and_split()
# 知识切片 将文档分割成均匀的块。每个块是一段原始文本
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
)
docs = text_splitter.split_documents(pages)
print(len(docs))
# 利用embedding模型对每个文本片段进行向量化,并储存到向量数据库中
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embed_model = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=docs, embedding=embed_model, collection_name="openai_embed")
# 通过向量相似度检索和问题最相关的K个文档。
query = "你知道Baichuan模型吗?"
result = vectorstore.similarity_search(query, k=5)
print(result)
# 原始`query`与检索得到的文本组合起来输入到语言模型,得到最终的回答
def augment_prompt(query: str):
# 获取top3的文本片段
results = vectorstore.similarity_search(query, k=3)
source_knowledge = "\n".join([x.page_content for x in results])
# 构建prompt
augmented_prompt = f"""Using the contexts below, answer the query.
contexts:
{source_knowledge}
query: {query}"""
return augmented_prompt
querys = augment_prompt(query)
print(querys)
prompt = PromptTemplate(
input_variables=["input"],
template="{input}",
)
rag_chain = LLMChain(llm=llm, prompt=prompt)
anst = rag_chain.run({
'input': query
})
print(f"回答如下:\n{anst}")
AnythingLLM 简介
AnythingLLM是一个全栈应用程序,您可以使用现成的商业大语言模型或流行的开源大语言模型,再结合托管数据库解决方案构建一个私有的ChatGPT,不再受制于人:您可以本地运行,也可以远程托管,并能够与您提供任何文档智能聊天。
AnythingLLM 支持多种文档类型(PDF、TXT、DOCX等),具有对话和查询两种聊天模式,在github上已经有接近14K star https://github.com/Mintplex-Labs/anything-llm
-
多用户支持和权限管理:允许多个用户同时使用,并可设置不同的权限。
-
支持多种文档类型:包括 PDF、TXT、DOCX 等。
-
简易的文档管理界面:通过用户界面管理向量数据库中的文档。
-
两种聊天模式:对话模式保留之前的问题和回答,查询模式则是简单的针对文档的问答
-
聊天中的引用标注:链接到原始文档源和文本。
-
完整的开发者 API:支持自定义集成。
-
嵌入模型支持:AnythingLLM 原生嵌入器、OpenAI、Azure OpenAI、LM Studio 和 LocalAI。
-
向量数据库支持:LanceDB(默认)、Pinecone、Chroma、Milvus、Weaviate 和 QDrant。
-
大模型模型支持:OpenAI、Azure OpenAI、Anthropic ClaudeV2、LM Studio 和 LocalAi。
anythingllm支持多种安装方式Docker、云,还有客户端,安装方式省略:
安装成功后界面:
api支持:http://localhost:3001/api/docs/
api_key支持
结合ollama使用,本地构建
- 使用ollama server模式,提供api给anythingllm使用
-
下载适合的大模型https://ollama.com/library
-
启动
ollama serve -
在设置llm大模型的时候可以选择ollama大模型
- 大模型选择:
-
选择openai 方式
-
选择本地ollama大模型方式
- 选择向量数据库:
-
自带的anything数据库
-
设置milvus数据库或者本地自有数据库 (milvus安装过程自行查阅)
实现效果:
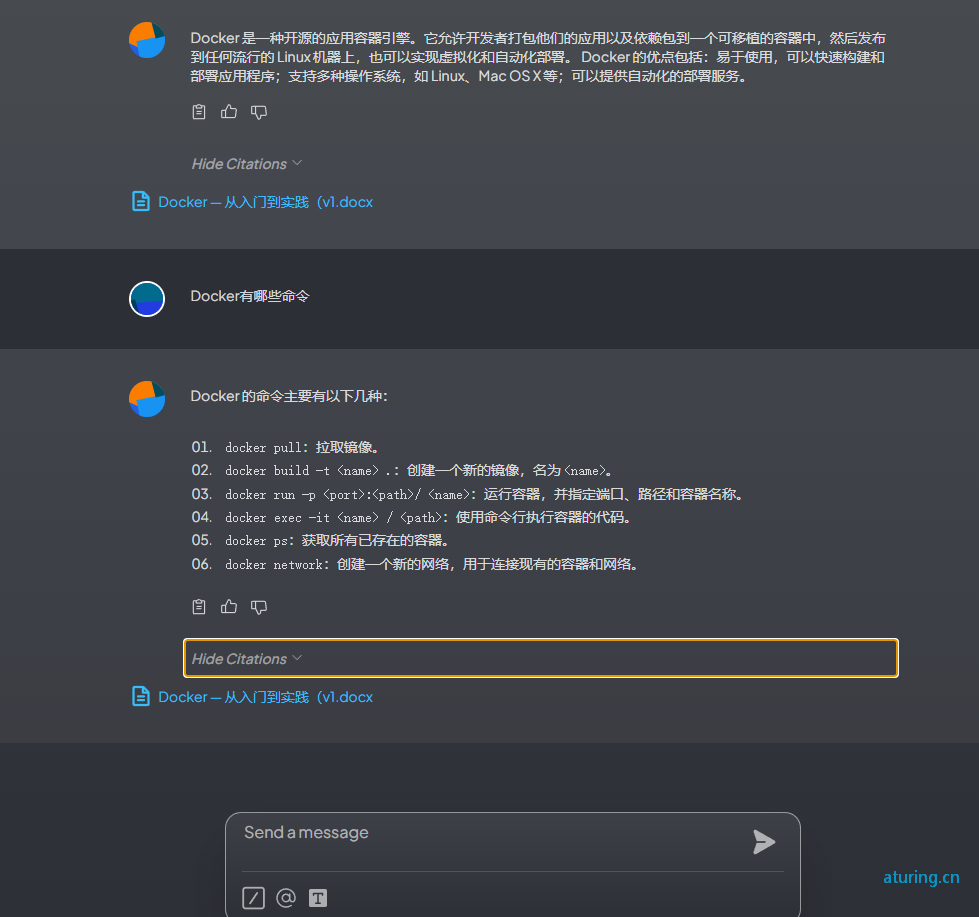
::: 所有的操作都可以通过基于api_key鉴权的api方式进行,而且还有类似环境的工作区,互不干扰
不同的向量数据库,已有数据需要清空,不然向量化入库后可能会有影响
本地运行大模型的时候,根据合适的配置选择模型大小 :::
提升RAG查询准确率一些手段
- Rerank重新排序:对初步检索得到的文档列表进行重新排序,以提高检索结果的质量。
-
更好分词分段:当一段话的结构和语义是完整的,并且是单一的,精度也会提高。因此,许多系统都会优化分词器,尽可能的保障每组数据的完整性。
-
精简
index的内容,减少向量内容的长度:当index的内容更少,更准确时,检索精度自然会提高。但与此同时,会牺牲一定的检索范围,适合答案较为严格的场景。 -
丰富
index的数量,可以为同一个chunk内容增加多组index。 -
优化检索词:在实际使用过程中,用户的问题通常是模糊的或是缺失的,并不一定是完整清晰的问题。因此优化用户的问题(检索词)很大程度上也可以提高精度。
-
微调向量模型:由于市面上直接使用的向量模型都是通用型模型,在特定领域的检索精度并不高,因此微调向量模型可以很大程度上提高专业领域的检索效果
使用场景思考
本地大模型使用场景思考:接口文档助手、内部机器人等等
- 上一篇: Stable Diffusion Webui教程
- 下一篇: golang字符串4种拼接方式对比
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论