Stable Diffusion Webui教程
Stable Diffusion Webui教程
1. 基本介绍
Stable Diffusion(SD)模型是由Stability AI和LAION等公司共同开发的生成式模型,总共有1B左右的参数量,可以用于文生图,图生图,图像inpainting,ControlNet控制生成,图像超分等丰富的任务,可以帮助我们快速创建高品质的绘画作品,还提供了一些高级功能,例如批量处理、自动矫正和自动化调整等。
基本原理:
文本信息如何成为SD模型能够理解的机器数学信息?
SD模型存在一个文本信息与机器数据信息之间互相转换的“桥梁”——CLIP Text Encoder模型。如下图所示,我们使用CLIP Text Encoder模型作为SD模型的前置模块,将输入的人类文本信息进行编码,输出特征矩阵,这个特征矩阵与文本信息相匹配,并且能够使得SD模型理解,完成对文本信息的编码后,就会输入到SD模型的“图像优化模块”中对图像的优化进行“控制”。

图像优化模块
“图像优化模块”是由一个U-Net网络和一个Schedule算法共同组成,U-Net网络负责预测噪声,不断优化生成过程,在预测噪声的同时不断注入文本语义信息。而schedule算法对每次U-Net预测的噪声进行优化处理(动态调整预测的噪声,控制U-Net预测噪声的强度),从而统筹生成过程的进度。在SD中,U-Net的迭代优化步数大概是50或者100次,在这个过程中Latent Feature的质量不断的变好(纯噪声减少,图像语义信息增加,文本语义信息增加)。整个过程如下图所示
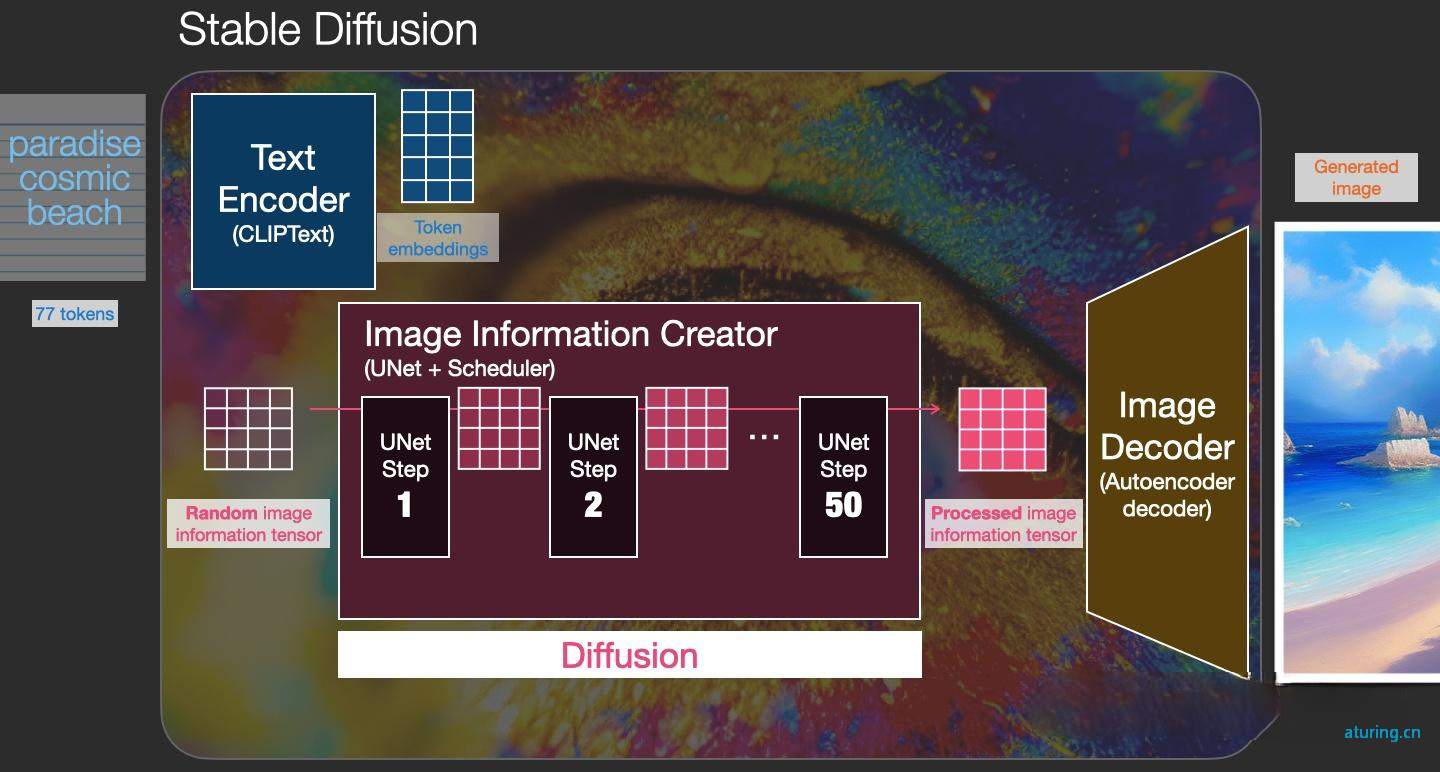
Stable Diffusion与Midjourney的比较:
对比两款AI绘画软件,Stable Diffusion(SD)具有更高的可 控性,而Midjourney(MJ)更偏向随机性。因此,使用SD可以 更精确地控制绘画的结果,而使用MJ则更加随机化和不确定,可能会有更多惊喜和变 化。此外,Stable Diffusion开源免费、自定义Lora模型更加具有可扩展性可玩性。


1.1 安装
官方地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui 秋叶包:https://pan.baidu.com/s/1Wvi8MIcoqcpn8SaovDl2Ug?pwd=gvfy
硬件要求
| 最低配置 | 推荐配置 | |
|---|---|---|
| 显卡 | NVIDIA独显4G | NVIDIA独显8G+ |
| 内存 | 8G+ | 16G |
| 硬盘 | 20G+ | 40G+ |
Python环境推荐3.10.6版本
安装CUDA,查看版本 nvcc --version,下载地址:https://developer.nvidia.com/cuda-toolkit-archive
启动命令:
webui-user.bat --n_samples 1
一些参数说明
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--lowvram --precision full --no-half --skip-torch-cuda-test --api
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:128
-
--port:端口,默认7860 -
--listen:默认0.0.0.0主机名称 -
--medvram:牺牲速度,换取较小的VRAM占用 -
--lowvram:大幅牺牲速度,换取更小的VRAM占用(GPU小于4G建议加上) -
--lowram:将模型的权重加载至VRAM,而非RAM -
--api:开启api接口 -
--share:使用此参数在启动后会产生Gradio网址,使WebUI能从外部网络访问
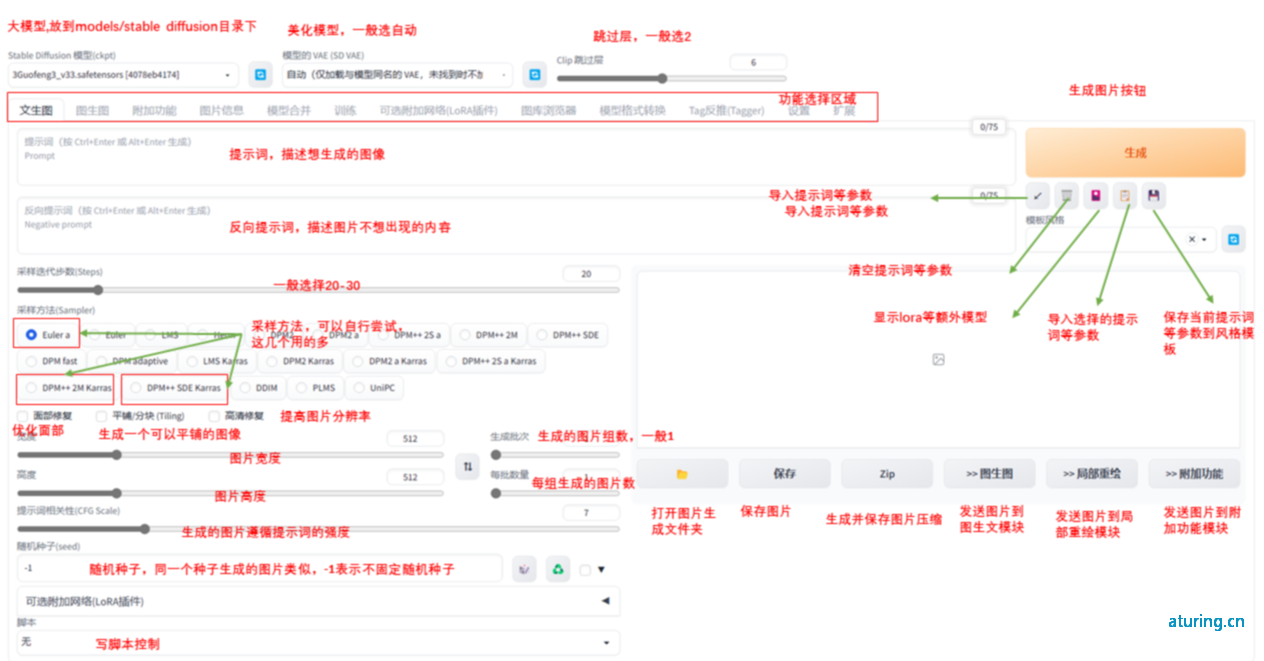
启动后的主界面:
1.2 启用本地api接口
启动的时候加上**--api**
接口文档默认地址:http://127.0.0.1:7860/docs
api接口:
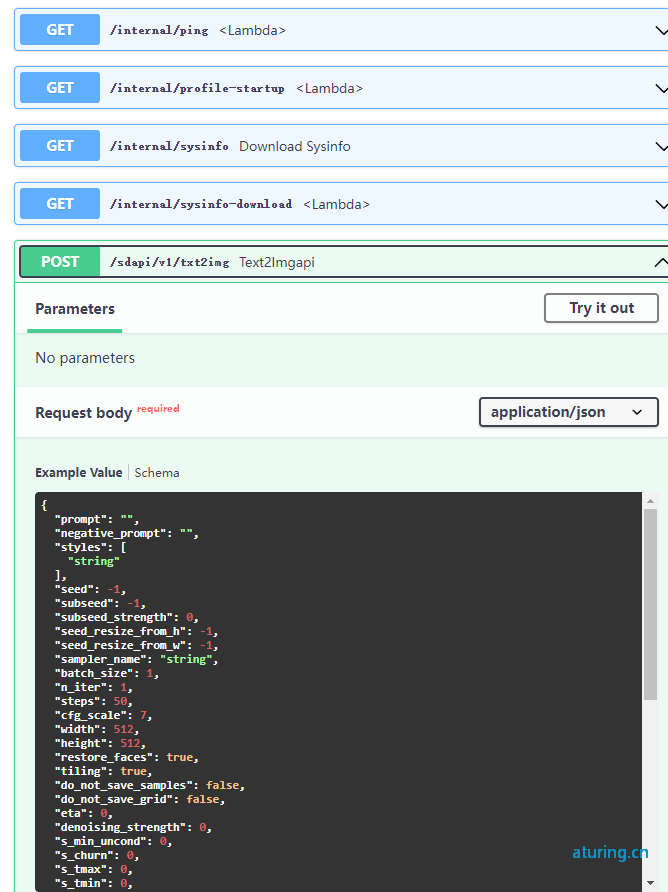
文生图接口:
POST http://127.0.0.1:7860/sdapi/v1/txt2img HTTP/1.1
Content-Type: application/json
{
"denoising_strength": 0,
"prompt": "1girl", //提示词
"negative_prompt": "", //反向提示词
"seed": -1, //种子,随机数
"batch_size": 2, //每次张数
"n_iter": 1, //生成批次
"steps": 50, //生成步数
"cfg_scale": 7, //关键词相关性
"width": 512, //宽度
"height": 512, //高度
"restore_faces": false, //脸部修复
"tiling": false, //可平埔
"override_settings": {
"sd_model_checkpoint": "sd-v1-4.ckpt [fe4efff1e1]"
}, // 生成图片的stable diffusion 模型
"script_args": [
0,
true,
true,
"LoRA",
"dingzhenlora_v1(fa7c1732cc95)",
1,
1
], // 一般用于lora模型或其他插件参数,如示例,我放入了一个lora模型, 1,1为两个权重值,一般只用到前面的权重值1
"sampler_index": "Euler" //采样方法
}
图生图接口:
base64图片 和模型替换成自己的
POST http://127.0.0.1:7860/sdapi/v1/img2img HTTP/1.1
Content-Type: application/json
{
"enable_hr": true,
"prompt": "make it cry",
"seed": -1,
"batch_size": 1,
"n_iter": 1,
"steps": 45,
"negative_prompt": "",
"cfg_scale": 60.0,
"width": 512,
"height": 512,
"restore_faces": false,
"sampler_index": "DPM++ 2M Karras",
"sampler_name": "DPM++ 2M Karras",
"denoising_strength": 0.5,
"hr_scale": 1.5,
"hr_second_pass_steps": 30,
"hr_upscaler": "Nearest",
"override_settings": {
"sd_model_checkpoint": "majicMIX realistic 麦橘写实_v7.safetensors"
},
"init_images": [
"xxx"
],
"override_settings_restore_afterwards": true,
"alwayson_scripts": {
"controlnet": {
"args": [
{
"input_image": "xxx",
"module": "canny",
"model": "control_v11p_sd15_canny [d14c016b]",
"weight": 1.0,
"mask": "xxx",
"resize_mode": "Scale to Fit (Inner Fit)",
"lowvram": false,
"processor_res": 640,
"threshold_a": 0.0,
"threshold_b": 255.0,
"guidance": 1.0,
"guidance_start": 0.0,
"guidance_end": 1.0,
"guessmode": false
}
]
}
}
}
other...
1.3 一些关键参数:
-
采样器(method):选择生成图像的采样算法,通常根据模型作者推荐的方式选择即可。
-
采样步数(steps):控制图像生成的迭代次数,数值越高则图像精细度越高,建议在20~30之间。
-
宽高(height/width):控制图像尺寸,图像过小则内容不够清晰,过大会占用更多显卡资源,且绘制图像可能出错,建议控制在512~1024之间。
-
提示词相关性(CFG scale): 控制图像和提示词描述的相关程度,建议控制在7~12 之间,数值太高容 易变形
-
种子(seed):生成图片过程中所产生的随机数,控制图片生成的多样性(固定时生成的图片将一样)
-
权重:最直接的权重调节就是调整词语顺序,越靠前权重越大,越靠后权重越低
可以通过下面的语法来对关键词设置权重,一般权重设置在0.5~2之间,可以通过选中词汇,按ctrl+↑↓来快速调 节权重,每次步进为0.1
以下方式也是网上常见的权重调节方式
(best quality)=(best quality:1.1)
(best quality)=(best quality:1.21),月即(1.1*1.1)
[best quality]=(best quality:0.91)
1.4 采样方法技巧
1. 建议根据自己使用的checkpoint使用脚本跑网格图(用自己关心的参数)然后选择自己想要的结果。
2. 一般情况下使用DPM++ 2M或DPM++ 2M Karras或UniPC,想要点惊喜和变化,Euler a、DPM++ SDE、DPM++ SDE Karras、DPM2 a Karras
3. eta(noise multiplier) 和sigma都是多样性相关的,但是它们的多样性来自步数的变化,追求更大多样性的话应该关注seed的变化,这两项参数应该是在图片框架被选定后,再在此基础上做微调时使用的参数。
1.5 使用中文prompt
自动翻译插件:
https://github.com/ParisNeo/prompt_translator
自动补齐:
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git
插件能汉化 UI 界面、Tag 自动补全、提示词 prompt 翻译等功能,解决英文不好的问题,有效减少用翻译软件的时间,不过测试发现词库并不全,有些可能还会用到翻译软件。
自动翻译prompt:
https://aiodoc.physton.com/zh-CN/AutomaticTranslation.html
2. 功能介绍
2.1 文生图
prompt:1girl,sweater,white background,
Negative prompt: (worst quality:2),(low quality:2),(normal quality:2),lowres,watermark,
Steps: 20,
Size: 512x512,
Seed: 501503578,
Model: majicMIX realistic (liblib上下载的),
Sampler: DPM++ 2M Karras,
CFG scale: 7,
Clip skip: 2
2.2 图生图
-
CLP反推提示词:生成自然语言式的提示词
-
DeepBooru反推提示词:生成关键词组提示词
-
重绘强度/Denoising strength
这个参数决定了我们重绘幅度,也就是说参数越高,幅度越大,图片生成差距越大。
具体看演示
涂鸦绘制(sketch)
步骤:图生图=》上传图片=》涂鸦》绘制(重绘强度0.5、少量修饰词)
局部绘制(inpaint)
2.3 图片高清放大
3. 模型介绍
3.1 各类模型
Checkpoint大模型: 通过使用素材和SD低模生成的深度学习大模型,可以直接应用于生成图像。大模型是创作的核心素材,决定了最终作品的方向和风格。这些大模型的扩展名一般为CKPT或SAFETENSORS。
Vae: VAE是对大模型的补充,类似于滤镜,可以稳定画面的色彩范围,提高作品的美观度,美化图片色彩。VAE的扩展名一般为CKPT或SAFETENSORS。
Embedding:
Embedding 又名 textual inversion 中文名:“嵌入或文本反转”。在 Stable Diffusion 中,Embedding 技术就可以被理解为一种组件,它可以将输入数据转换成向量表示,方便模型进行处理和生成,常用于控制人物的动作和特征,或者生成特定的画风,主要用于文本理解能力。
Lora: LoRA是一种模型插件,需要在基于某个大模型的基础上进行深度学习后生成小型模型。需要与大模型配合使用,可以在涵盖中小范围内的风格上产生影响或增加大模型缺失的元素。主要用于特定的功能定制。LoRA的扩展名一般为CKPT或SAFETENSORS。
**Hypernetwork超网络:**功能与embedding、lora类似,都是会对图片画风进行针对性的调整,可以简单的理解为低配版的lora,所以它的适用范围比较窄,主要用于定制画风、风格,也可以生成特定的模型和人物。使用方式:hypernet:mjv4Hypernetwork\_v1:1
ControlNet: ControlNet是一个神级插件,让SD具备了分析图片中线条和景深等信息的能力,并反推到处理图片上。这对于创作出真正自然、真实的图像非常有用。
常见的模型下载地址:
各类模型默认存放位置:
Checkpoint:
xx/stable-diffusion-webui/models/Stable-diffusion
Vae:
xx/stable-diffusion-webui/models/Vae
Emdding:
xx/stable-diffusion-webui/models/emddings
Lora
xx/stable-diffusion-webui/models/lora
....
4. 提示词
4.1 提示词类型
- 正向提示词****Prompts :
用于生成图片的提示词
2. 负向提示词 Negative Prompts:
生图时常常还需要加入一些负向提示词,避免掉不好的结果。AI绘图有时不会一次就算出好结果,所以还需要加上负向提示词来控制,尤其是大批算图的时候更为重要。
负向提示词会加入一些常见的「不友好」的图片特征,例如低画质、最糟品质、画家签名、模糊、浮水印;不想看到裸露、兵器、血、猎奇的元素出现,就加入nsfw、weapon、blood、guro等负向提示词
4.2 提示词撰写技巧
质量+主体+动作场景+风格+细节补充
-
质量:代表画面的品质,如1girl结合high quality使用来获得高质量图像。
-
主体:画面主要内容,这是任何提示的基本组成部分
-
代表动作/场晏:描述了主体在哪里做了什么。
-
风格:画面风格(可选)
-
细节补充:可以使用艺术家,工作室,摄影术语,角色名字,风格,特效等等
示例:
正向提示词
masterpiece,best quality,solo,1girl,upper body,beautyful face,seductive smile,blush,star-shaped pupils,earrings,sitting,back,garden,flower,(branch),photorealistic,highres,4k,8k,bokeh
反向提示词
lowres,bad anatomy,bad hands,text,error,missing fingers,extra digit,fewer digits,cropped,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,username,blurry
4.3 使用Embedding
相比于其他模型来说(如 LORA),Embedding 文件的大小只有几十 KB。除了还原度对比 LORA 差一些外,在存储和使用上却更方便。
比如我们要生成一个这样的图片,可能要输入一堆提示词
masterpiece, high-quality,1girl,clothes with Pink pattern,(brown hair), pinkearphones, green pattern on the earphones, blue tights, white gloves, ((pinkpattern on the clothes)), cat pattern on the face, detailed eyes, (pink theme), rabbitdecoration on the chest, green word pattern, sewing line on the clothes, long hair.thin girl, delicate face, beautiful face, melon face, skin full of details, pinkbackground, white gloves, thin neck, Sexy figure, (brown eyes:1.2), smile, wearingwhite shoes, green patterns, blushing。。。。
但是如果使用Embedding ,只需要:
masterpiece, high-quality,corneo dva
安装
Embedding的安装使用也特别简单,下载Embedding的pt文件放到Embedding文件夹下面
5. ControlNet 的使用
ControlNet是一个神级插件,让SD具备了分析图片中线条和景深等信息的能力,并反推到处理图片上,对创作出真正自然、真实的图像非常有效。
常用模型下载地址:
https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
下载后模型存放位置:xxx/extensions/sd-webui-controlnet/models
使用场景和演示:
5.1 Canny 边缘检测
Canny 是比较常用的一种线稿提取方式,该模型能够很好的识别出图像内各对象的边缘轮廓。
使用说明(以下其它模型同理):
-
展开 ControlNet 面板,上传参考图,勾选 Enable 启用(如果显存小于等于 4G,勾选低显存模式)。
-
预处理器选择 Canny(**注意:**如果上传的是已经经过预处理的线稿图片,则预处理器选择 none,不进行预处理),模型选择对应的 control_v11p_sd15_canny 模型。
-
勾选 Allow Preview 允许预览,点击预处理器旁的
- 上一篇: Kubernetes零宕机发布应用
- 下一篇: golang字符串4种拼接方式对比
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论