elasticsearch基本介绍
基本介绍
Elasticsearch 很快。 由于 Elasticsearch 是在 Lucene 基础上构建而成的,所以在全文本搜索方面表现十分出色。Elasticsearch 同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。因此,Elasticsearch 非常适用于对时间有严苛要求的用例,例如安全分析和基础设施监测。
本质特征
Elasticsearch 中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,以防发生硬件故障。Elasticsearch 的分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。
Elasticsearch 包含一系列广泛的功能。 除了速度、可扩展性和弹性等优势以外,Elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
Elastic Stack 简化了数据采集、可视化和报告过程。 通过与 Beats 和 Logstash 进行集成,用户能够在向 Elasticsearch 中索引数据之前轻松地处理数据。同时,Kibana 不仅可针对 Elasticsearch 数据提供实时可视化,同时还提供 UI 以便用户快速访问应用程序性能监测 (APM)、日志和基础设施指标等数据。
-
性能差问题 如果表记录上千万上亿搜索,如果模糊匹配会出现现严重的性能问题。
-
分词搜索 不能将搜索词拆分开来,比如上面这个只能搜索名字是“张三”开头的员工,如果想搜出“张小三”那是搜索不出来的。
Elasticsearch是使用Java编写的一种开源搜索引擎,它在内部使用Luence做索引与搜索,通过对Lucene的封装,提供了一套简单一致的RESTful API。
Elasticsearch也是一种分布式的搜索引擎架构,可以很简单地扩展到上百个服务节点,并支持PB级别的数据查询,使系统具备高可用和高并发性。
- Elasticsearch基于Lucene构建,Elasticsearch利用Lucene做实际的工作
- ELasticsearch中的每个分片都是一个分离的Lucene实例.
- Elasticsearch在Lucene基础上(即利用Lucene的功能)提供了一个分布式的、基于JSON的REST API 来更方便地使用 Lucene的功能。
- Elasticsearch提供其他支持功能,如线程池,队列,节点/集群监控API,数据监控API,集群管理等
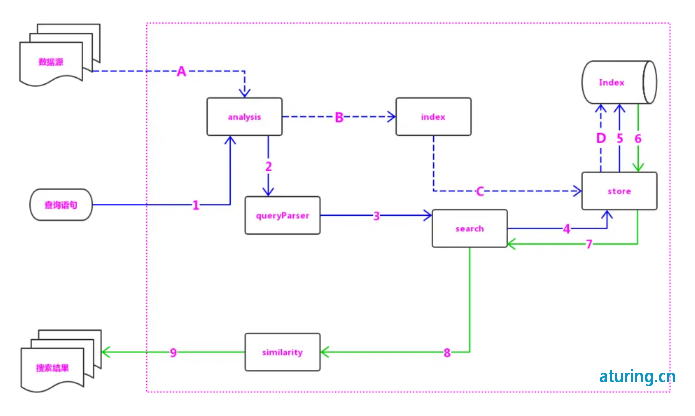
核心概念
索引(index):ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。
类型(type):类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”。
文档(document):文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
Replicas:备份也叫作副本,是指对主分片的备份。主分片和备份分片都可以对外提供查询服务,写操作时先在主分片上完成,然后分发到备份上。当主分片不可用时,会在备份的分片中选举出一个作为主分片,所以备份不仅可以提升系统的高可用性能,还可以提升搜索时的并发性能。但是若副本太多的话,在写操作时会增加数据同步的负担。
映射(mapping):ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。另外,ES还提供了额外功能,例如将域中的内容按需排序。事实上,ES也能自动根据其值确定域的类型。
节点(node):运行了单个实例的ES主机称为节点,它是集群的一个成员,可以存储数据、参与集群索引及搜索操作。类似于集群,节点靠其名称进行标识,默认为启动时自动生成的随机Marvel字符名称。用户可以按需要自定义任何希望使用的名称,但出于管理的目的,此名称应该尽可能有较好的识别性。节点通过为其配置的ES集群名称确定其所要加入的集群。
分片(shard):ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。
字段(Fields):每个Document都类似一个JSON结构,它包含了许多字段,每个字段都有其对应的值,多个字段组成了一个 Document,可以类比关系型数据库数据表中的字段。
倒排索引
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况
倒排列表数据结构:
- (DocID;TF;
) - DocID:出现单词文档ID
- TF(Term Frequency):单词在该文档中出现的次数
- POS:单词在文档中的位置
es安装
单例安装ES服务: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.2.tar.gz
tar -vxf 解压
cd elasticsearch-5.5.2
启动:./bin/elasticseatch
安装IK分词 elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.3/elasticsearch-analysis-ik-6.5.3.zip
卸载:elasticsearch-plugin remove analysis-ik; 查看所有插件: elasticsearch-plugin list
elasticsearch在php中的使用
- 安装: composer require elasticsearch/elasticsearch
- 实例化客户端 use Elasticsearch\ClientBuilder;$client=ClientBuilder::create()->build();
- 索引一个文档(创建一条数据): $client->index($params);
- 获取一个文档(查询一条记录): $client->get($params);
- 搜索一个文档(全文搜索): $client->search($params);
- 删除一个文档(删除记录): $client->delete($params);
- 删除索引(删库): $client->indices()->delete($deleteParams);
- 创建索引(创建数据库): $client->indices()->create($params);
插件包https://github.com/medcl/elasticsearch-rtf 运行环境:JDK8+;系统可用内存>2G 运行: cd elasticsearch/bin Mac/Linux: ./elasticsearch Windows: elasticsearch.bat 可根据需卸载( elasticsearch-plugin remove + 插件名称)无关的插件,重启 elasticsearch 生效,减少内存消耗。 http://localhost:9200/ 访问如下表面es安装启动成功
Laravel扩展包
- Laravel Scout 为 Eloquent 模型 全文搜索提供了简单的,基于驱动的解决方案。
- Laravel Scout通过使用模型观察者,在Model中use Searchable; Scout 会自动同步 Eloquent的记录到搜索索引。
- php artisan scout:import “App\Post“ 导入数据到索引
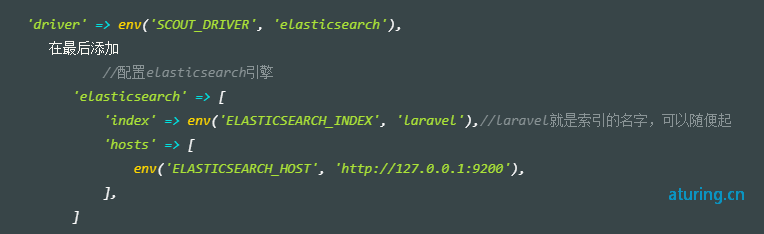
- Scout默认的是Algolia驱动,在scout.php配置中可选elasticsearch驱动
安装Scout
composer require laravel/scout 在config/app.php 的 providers 数组中添加 Laravel\Scout\ScoutServiceProvider::class php artisan vendor:publish --provider="Laravel\Scout\ScoutServiceProvider
安装 laravel-scout-elastic
composer require tamayo/laravel-scout-elastic 在 config/app.php 的 providers 数组中添加ScoutEngines\Elasticsearch\ElasticsearchProvider::class
修改 scout.php 文件
elasticsearch 的索引和模板建立
- php artisan make:command Esinit//创建索引脚本
- 编写handle方法(详细见代码)
- php artisan scout:import ‘\App\Artcile’ 导入articles表数据
- php artisan scout:flush ‘\App\Post’ 清空数据
- 本地通过http://localhost:9200/laravel/articles/2 访问数据//域名+索引+type类型+ID
通过search关键词搜索数据
- 要实现多模型查询,可以在模型初始化时改变配置的索引。比如使用 ElasticSearch 驱动时,驱动包默认是取 scout.elasticsearch.index 的配置值作为索引,所以在模型的 __construct 方法中改变这个配置值,就可以实现多模型查询
Mapping
-
概念: 自动或手动为index中的type建立的一种数据结构和相关配置,简称为mapping
-
text 文本类型
-
index: analyzed 分词,不分词是:not_analyzed ,设置成false,字段将不会被索引
-
analyzer: ik_max_word 指定分词器
-
boost:1.23 字段级别的分数加权
-
doc_values:false 对not_analyzed字段,默认都是开启,analyzed字段不能使用,对排序和聚合能提升较大性能,节约内存,如果您确定不需要对字段进行排序或聚合,或者从script访问字段值,则可以禁用doc值以节省磁盘空间:
-
fielddata:{"loading" : "eager" } Elasticsearch 加载内存 fielddata 的默认行为是 延迟 加载 。 当 Elasticsearch 第一次查询某个字段时,它将会完整加载这个字段所有 Segment 中的倒排索引到内存中,以便于以后的查询能够获取更好的性能。
-
fields:{"keyword": {"type": "keyword","ignore_above": 256}} 可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词
-
ignore_above:100 超过100个字符的文本,将会被忽略,不被索引
-
include_in_all:ture 设置是否此字段包含在_all字段中,默认是true,除非index设置成no选项
-
index_options:docs 4个可选参数docs(索引文档号) ,freqs(文档号+词频),positions(文档号+词频+位置,通常用来距离查询),offsets(文档号+词频+位置+偏移量,通常被使用在高亮字段)分词字段默认是position,其他的默认是docs
-
norms:{"enable":true,"loading":"lazy"} 分词字段默认配置,不分词字段:默认{"enable":false},存储长度因子和索引时boost,建议对需要参与评分字段使用 ,会额外增加内存消耗量
-
null_value:NULL 设置一些缺失字段的初始化值,只有string可以使用,分词字段的null值也会被分词
-
position_increament_gap:0 影响距离查询或近似查询,可以设置在多值字段的数据上火分词字段上,查询时可指定slop间隔,默认值是100
-
store:false 是否单独设置此字段的是否存储而从_source字段中分离,默认是false,只能搜索,不能获取值
-
search_analyzer:ik 设置搜索时的分词器,默认跟ananlyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能
ik分词器
ik_max_word :会将文本做最细粒度的拆分;尽可能多的拆分出词语 ik_smart:会做最粗粒度的拆分;已被分出的词语将不会再次被其它词语占有 推荐另外一个laravel中文分词package https://github.com/baijunyao/laravel-scout-elasticsearch/tree/v3.0.1
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论