MySQL慢查分析
慢查表现特征
1,数据库CPU负载高,一般是查询语句中有很多计算逻辑,导致数据库cpu负载。 2,IO负载高导致服务器卡住。这个一般和全表查询没索引有关系。 3,查询语句正常,索引正常但是还是慢。如果表面上索引正常,但是查询慢,需要看看是否索引没有生效。
开启慢查
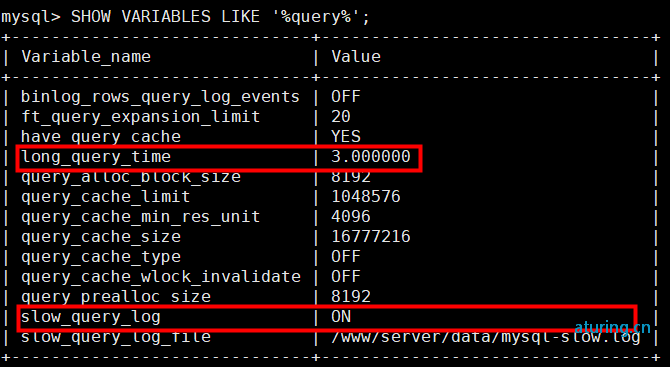
关于慢查询日志,主要涉及到下面几个参数:
slow_query_log :是否开启慢查询日志功能(必填) long_query_time :超过设定值,将被视作慢查询,并记录至慢查询日志文件中(必填) log-slow-queries :慢查询日志文件(不可填),自动在 \data\ 创建一个 [hostname]-slow.log 文件
也就是说,只有满足以上三个条件,“慢查询功能”才可能正确开启或关闭
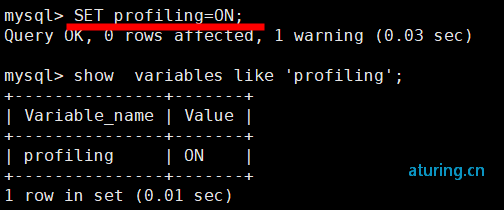
开启profile分享
调用explain分析

各项参数分析

索引的选择
主键索引
主键用来区分,查找,和关联数据,非常重要.
- 在myisam中,字符串索引会被压缩,用字符串做主键性能不如整型
- 用递增的值,不要用离散的值,离散值会导致文件在磁盘的位置有间隔,浪费空间且不易连续读取
- UUID,也是逐步增长的,可以去掉"-",转换为整数
1: 定长与变长分离 如 id int, 占4个字节, char(4) 占4个字符长度,也是定长, time 即每一单元值占的字节是固定的。 核心且常用字段,宜建成定长,放在一张表。 而varchar, text,blob,这种变长字段,适合单放一张表, 用主键与核心表关联起来.
2:常用字段和不常用字段要分离. 需要结合网站具体的业务来分析,分析字段的查询场景,查询频度低的字段,单拆出来.
3:合理添加冗余字段. 看如下BBS的效果
字段类型优先级: int > date,time > char,varchar > blob 2:够用就行,不要慷慨 (如smallint,varchar(N)) 3:尽量避免用NULL
理想索引标准: 1: 查询频繁 2:区分度高 3:长度小 4:尽量能覆盖常用查询字段
索引建立原则
1.最左前缀匹配原则,非常重要的原则,ysq会一直向右匹配直到遇到范围查询(>、<、between、ike)就停止匹配,比如a=1 and b=2 and c>3and d=4如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整;
2.=和in可以乱序,比如a=1 and b=2 and c=3建立(a,b,c索可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式;
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要o的字段我们都要求是0.1以上,即平均1条扫描10条记录; 4.索引列不能参与计算,保持列"干净",比如from unixtime(create time)='2014-05-29'就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create time unix timestamp(2014-05-29);
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
- 上一篇: MySQL分库分表
- 下一篇: elasticsearch基本介绍
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论