RAG优化
RAG概述
RAG,即"Retrieval-Augmented Generation",是一种结合了检索(Retrieval)和生成(Generation)的机器学习模型框架。它广泛应用于自然语言处理任务,如文本生成和问答系统等。RAG模型首先通过检索机制从大型文档集合中检索出与输入查询最相关的文档或文档片段,然后利用这些信息作为上下文,输入到生成模型中,以生成响应或完成特定的语言任务。RAG的优势在于能够利用外部知识库提供的信息,提高生成内容的准确性和相关性,同时减少对大量标注数据的依赖。
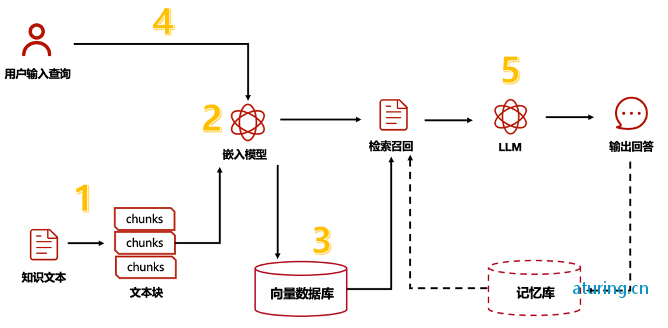
RAG的应用场景
RAG因其高效的信息整合与生成能力,在以下领域展现出广泛的应用潜力:
- 问答系统:提供准确和信息丰富的答案,尤其是在处理需要跨文档推理的问题时。
- 对话系统:增强聊天机器人的应答能力和上下文理解,使对话更加自然流畅。
- 文本摘要:生成全面且贴近原文的摘要,通过检索多源信息提高摘要质量。
- 知识图谱补全:利用检索到的相关信息辅助生成缺失的实体关系,丰富知识图谱内容。
RAG与大型语言模型(LLM)
尽管大型语言模型(LLM)可以处理无限上下文,RAG仍然具有其独特的价值:
- RAG可以解决大模型的幻觉问题,并通过外挂知识避免模型频繁进行知识更新。
- 即使LLM的上下文长度可达128k,但知识库中可能包含远超此长度的文档,因此检索仍然必要。
- 对于具体问题,传递过多内容可能导致结果变差。与问题不相干的内容可能有害无益。
RAG的优化方案
提高向量搜索精度的方法
- 更好分词分段:优化分词器,保障数据的完整性。
- 精简index内容:减少向量内容的长度,提高检索精度,但可能牺牲检索范围。
- 丰富index数量:为同一内容增加多组index。
- 优化检索词:优化用户的问题(检索词)以提高精度。
- 微调向量模型:针对特定领域微调向量模型以提高检索效果。
构建知识库方案
数据召回,pgsql索引
使用HNSW索引创建多层图,提高查询性能。可以通过设置动态候选列表的大小来平衡召回率和查询速度。
SET hnsw.ef_search = 100;
对比测试:
-- 查询
SET hnsw.ef_search = 50;
EXPLAIN ANALYZE
SELECT * FROM vector1s ORDER BY embedding <=> '[1.05,2.05,3.05]' LIMIT 3;
-- 查询
SET hnsw.ef_search = 200;
EXPLAIN ANALYZE
SELECT * FROM vector1s ORDER BY embedding <=> '[1.05,2.05,3.05]' LIMIT 3;
多向量
FastGPT采用多向量映射方式,将数据映射到多组向量中,保障数据的完整性和语义的丰富度。
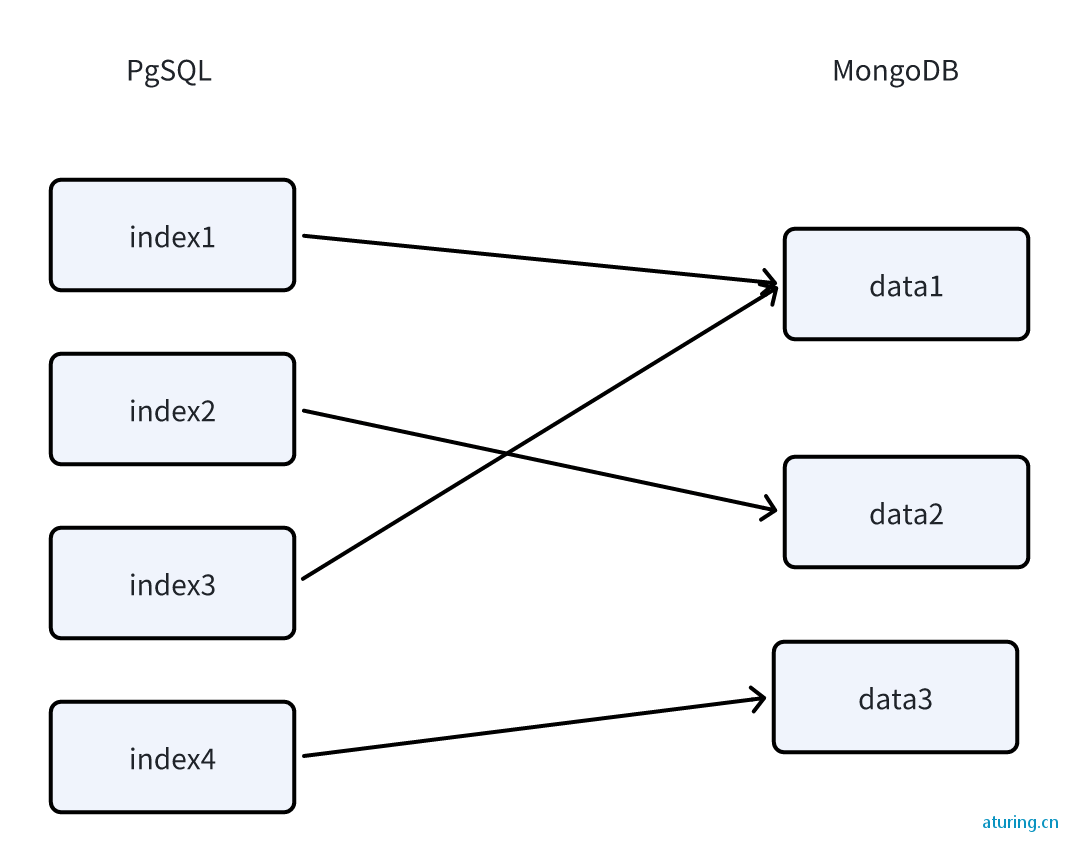
语义检索
语义检索通过向量距离计算用户问题与知识库内容的相似度,具有跨语言和多模态理解的优点,但也存在依赖模型训练效果和精度不稳定的问题。
全文检索
采用传统的全文检索方式,适合查找关键的主谓语等。可以通过配置不同的文本搜索配置来适应不同的语言需求。
混合检索
结合向量检索和全文检索,通过RRF公式合并搜索结果,提高搜索结果的丰富性和准确性。
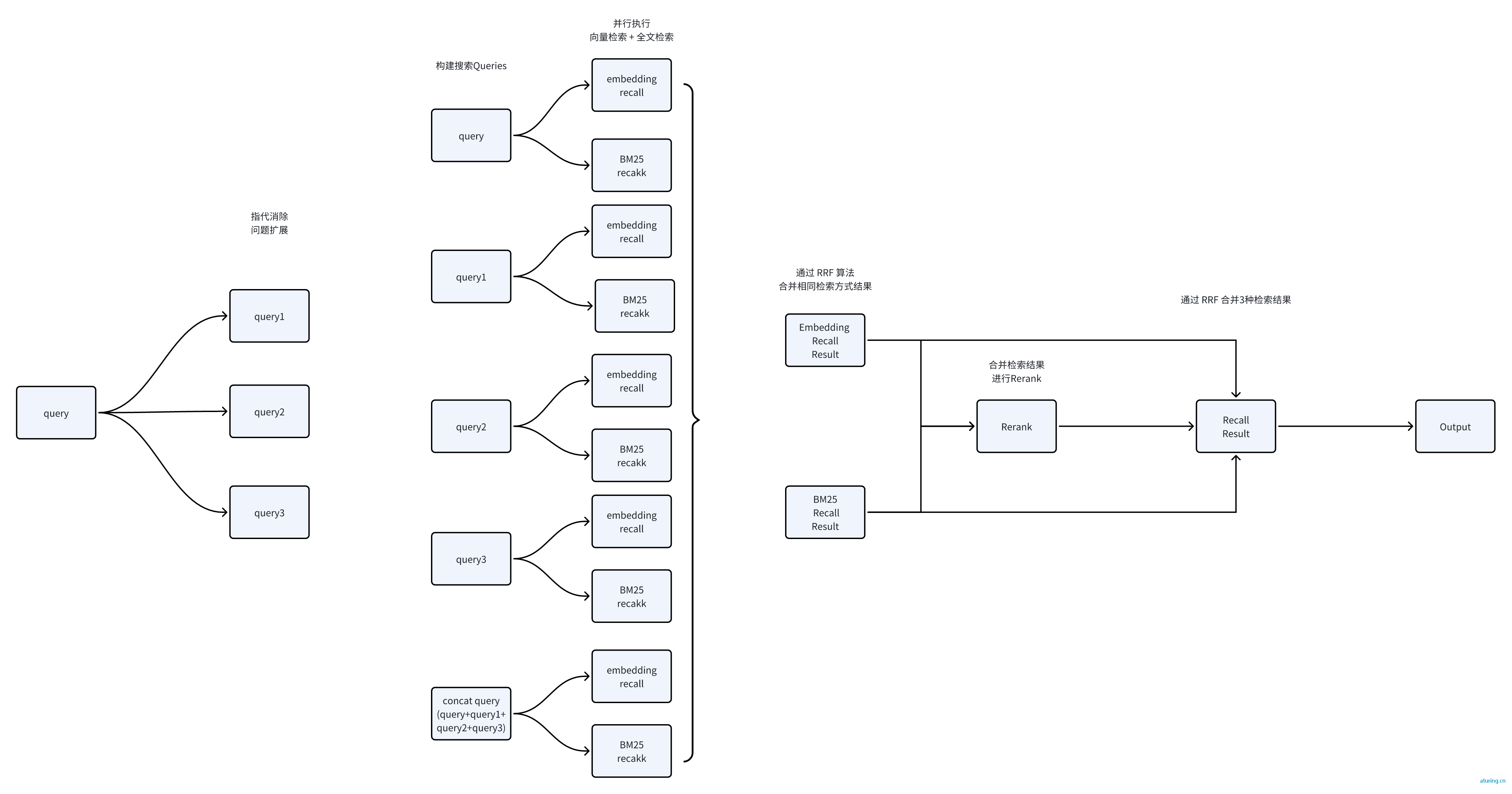
二次重排
使用ReRank模型对搜索结果进行重排,提高搜索结果的准确率。ReRank模型通过计算用户问题与文本的相似度,提供比向量模型更精确的排序结果。
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
打 赏
最新评论