MVVC多版本并发控制
MVCC概念
MVCC(多版本并发控制)是一种并发控制的方法,它对每一个读取的对象都生成一个“读时间点”的数据快照。 “不同的事务可以在同一时间看到同一张表中的不同数据” 在MySQL InnoDB存储引擎中,MVCC的实现通过在每一行记录后面保存两个字段来完成,这两个字段分别是:
创建版本号(CREATE VERSION NUMBER,CVN) 删除版本号(DELETE VERSION NUMBER,DVN) 每个事务有一个唯一的事务版本号,它是在事务开始时获取的。下面是它的工作方式:
1. READ COMMITTED隔离级别下的读操作:
对于普通SELECT(非锁定读),看到的是查询开始时已经提交的事务所做的修改。 对于SELECT FOR UPDATE、单表UPDATE/DELETE等锁定读,看到的是执行时已经提交的事务所做的修改。
2. REPEATABLE READ隔离级别下的读操作:
不论是普通读还是锁定读,看到的都是事务开始时已经提交的事务所做的修改。 当执行读操作时,对于一个数据版本,以下情况下认为该版本对当前事务可见:
该版本的CVN(创建版本号)小于等于当前事务版本号; 该版本的DVN(删除版本号)大于当前事务版本号,或者为空。 换言之,对于当前事务,该版本在其事务开始前已经存在,且在其事务运行过程中一直存在。
实现原理
对于 InnoDB ,聚簇索引记录中包含 3 个隐藏的列:
- ROW ID:隐藏的自增 ID,如果表没有主键,InnoDB 会自动按 ROW ID 产生一个聚集索引树。
- 事务 ID:记录最后一次修改该记录的事务 ID。
- 回滚指针:指向这条记录的上一个版本。
MVCC 的实现原理,如下图:
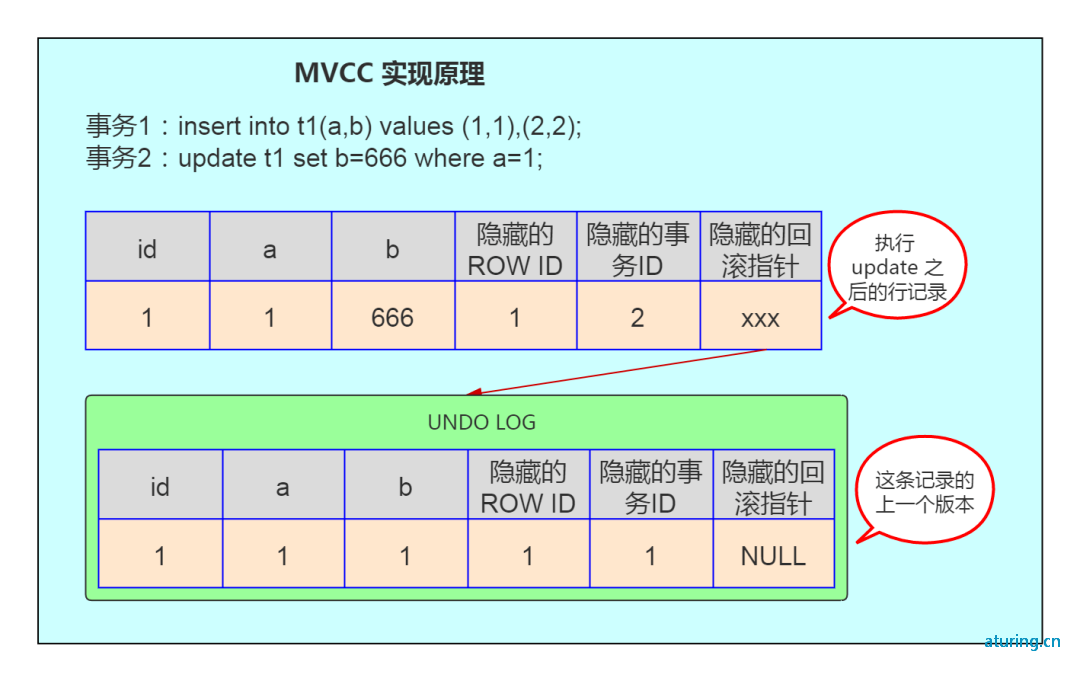
如图,首先 insert 语句向表 t1 中插入了一条数据,a 字段为 1,b 字段为 1, ROW ID 也为 1 ,事务 ID 假设为 1,回滚指针假设为 null。当执行 update t1 set b=666 where a=1 时,大致步骤如下:
- 数据库会先对满足 a=1 的行加排他锁;
- 然后将原记录复制到 undo 表空间中;
- 修改 b 字段的值为 666,修改事务 ID 为 2;
- 并通过隐藏的回滚指针指向 undo log 中的历史记录;
- 事务提交,释放前面对满足 a=1 的行所加的排他锁。
在前面实验的第 6 步中,session2 查询的结果是 session1 修改之前的记录,这个记录就是来自 undolog 中。
因此可以总结出 MVCC 实现的原理大致是:
InnoDB 每一行数据都有一个隐藏的回滚指针,用于指向该行修改前的最后一个历史版本,这个历史版本存放在 undo log 中。如果要执行更新操作,会将原记录放入 undo log 中,并通过隐藏的回滚指针指向 undo log 中的原记录。其它事务此时需要查询时,就是查询 undo log 中这行数据的最后一个历史版本。
MVCC 最大的好处是读不加锁,读写不冲突,极大地增加了 MySQL 的并发性。通过 MVCC,保证了事务 ACID 中的 I(隔离性)特性。
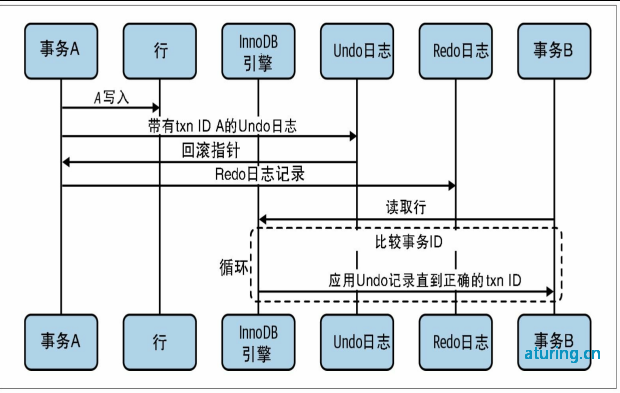
InnoDB通过为每个事务在启动时分配一个事务ID来实现MVCC。该ID在事务首次读取任何数据时分配。在该事务中修改记录时,将向Undo日志写入一条说明如何恢复该更改的Undo记录,并且事务的回滚指针指向该Undo日志记录。这就是事务如何在需要时执行回滚的方法。
当不同的会话读取聚簇主键索引记录时,InnoDB会将该记录的事务ID与该会话的读取视图进行比较。如果当前状态下的记录不应可见(更改它的事务尚未提交),那么Undo日志记录将被跟踪并应用,直到会话达到一个符合可见条件的事务ID。这个过程可以一直循环到完全删除这一行的Undo记录,然后向读取视图发出这一行不存在的信号。事务中的记录可以通过在记录的“info flags”中设置“deleted”位来删除。这在Undo日志中也被作为“删除标记”进行跟踪。
所有Undo日志写入也都会写入Redo日志,因为Undo日志写入是服务器崩溃恢复过程的一部分,并且是事务性的。[12]这些Redo日志和Undo日志的大小也是高并发事务工作机制中的重要影响因素。我们将在第5章更详细地介绍它们的配置。
在记录中保留这些额外信息带来的结果是,大多数读取查询都不再需要获取锁。它们只是尽可能快地读取数据,确保仅查询符合条件的行即可。缺点是存储引擎必须在每一行中存储更多的数据,在检查行时需要做更多的工作,并处理一些额外的内部操作。
MVCC仅适用于REPEATABLE READ和READ COMMITTED隔离级别。READ UNCOMMITTED与MVCC不兼容[13],是因为查询不会读取适合其事务版本的行版本,而是不管怎样都读最新版本。SERIALIZABLE与MVCC也不兼容,是因为读取会锁定它们返回的每一行。
因此,通过MVCC,可以实现读取操作无需加锁,从而提高数据库的并发性能。同时,每个事务都在操作其私有的数据快照,而不是直接操作数据库中的数据,因此避免了不可重复读和幻读等一系列问题。
- 上一篇: MySQL数据库的4种隔离级别
- 下一篇: golang字符串4种拼接方式对比
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论