browser-use基础及应用
Browser-Use 是一个开源的 AI 浏览器自动化框架,它让 AI 代理能够像人类一样自主地与网页进行交互。该项目基于 MIT 许可证,在 GitHub 上已获得超过 73.4k 星标,拥有活跃的开发者社区。
核心特性
-
AI 驱动的浏览器自动化:通过大语言模型(LLM)理解任务并自主决策
-
基于 Chromium CDP:使用 Chrome DevTools Protocol 进行底层浏览器控制
-
多模型支持:兼容 OpenAI、Anthropic、Google、本地模型等多种 LLM
-
云端部署能力:支持本地和云端浏览器实例
-
丰富的工具集:内置导航、点击、输入、数据提取等多种操作工具
技术架构
Browser-Use 采用分层架构设计:
┌─────────────────────────────────────┐
│ Agent Layer (任务规划) │
│ - 任务理解与分解 │
│ - LLM 决策引擎 │
│ - 历史记录管理 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ Tools Layer (工具层) │
│ - 浏览器操作工具 │
│ - 文件系统工具 │
│ - 自定义工具扩展 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ Browser Layer (浏览器层) │
│ - CDP 协议通信 │
│ - DOM 解析与序列化 │
│ - 页面状态管理 │
└─────────────────────────────────────┘
项目代码结构
Browser-Use 项目主要部分代码结构如下:
browser-use/
├── browser_use/ # 主要代码目录
│ ├── agent/ # AI 代理相关代码
│ ├── browser/ # 浏览器控制相关代码
│ ├── controller/ # 控制器和动作注册相关代码
│ ├── dom/ # DOM 操作和解析相关代码
│ └── telemetry/ # 遥测和数据收集相关代码
| └── llm/ # 模型对话相关
| └── mcp/ # mcp服务
| └── tools/ # 工具定义注册
.....
├── docs/ # 文档
├── examples/ # 使用示例
├── static/ # 静态资源
├── tests/ # 测试代码
agent 模块
agent 包是 Browser-Use 项目的核心组件,负责协调 LLM(大型语言模型)、浏览器和控制器之间的交互,实现 AI 代理控制浏览器的功能。 其主要功能包括:
-
任务规划与执行:根据用户提供的任务描述,规划并执行一系列浏览器操作。
-
状态管理:维护代理的状态信息,包括执行步骤、历史记录等。
-
消息管理:管理与 LLM 的消息交互,包括系统提示、用户消息和模型响应。
-
错误处理:处理执行过程中的各种错误,并提供重试机制。
-
历史记录:记录代理执行的每一步操作及其结果,便于分析和调试。
-
GIF 生成:可选功能,将代理操作过程记录为 GIF 动画。
controller 模块
controller 模块负责注册、管理和执行各种浏览器操作动作。它充当了 agent 包和 browser 包之间的桥梁,将 LLM 生成的指令转换为具体的浏览器操作。 其主要功能包括:
-
动作注册:提供装饰器机制,允许开发者注册自定义动作。
-
动作执行:执行已注册的动作,处理参数验证和错误处理。
-
动作管理:维护已注册动作的列表,提供动作描述和帮助信息。
-
参数验证:使用 Pydantic 模型验证动作参数,确保参数类型和格式正确。
-
默认动作提供:内置了一系列常用的浏览器操作,如导航、点击、输入文本等。
-
异步支持:支持同步和异步动作,自动将同步动作包装为异步
browser 模块
browser 模块负责浏览器的初始化、配置和控制。它封装了 Playwright 库的功能,提供了更高级的浏览器操作接口。 其主要功能包括:
-
浏览器初始化与配置:负责初始化浏览器实例,并根据配置设置浏览器参数。
-
浏览器上下文管理:创建和管理浏览器上下文,支持多标签页操作。
-
页面导航与交互:提供页面导航、元素交互等功能。
-
状态管理:维护浏览器状态,包括当前 URL、标题、标签页信息等。
-
DOM 操作:通过与 DOM 包的集成,提供 DOM 元素的查找、操作功能。
-
错误处理:处理浏览器操作过程中的各种错误。
dom 模块
dom 模块负责处理和表示浏览器的文档对象模型(Document Object Model),提供了以下主要功能:
-
DOM树构建与管理:通过DomService类,从浏览器页面中提取DOM结构并构建成树形结构。
-
可点击元素识别:识别和管理页面中的可点击元素,支持用户交互。
-
DOM历史记录处理:通过HistoryTreeProcessor服务,处理DOM元素的历史记录,支持元素的跟踪和比较。
-
视口信息管理:跟踪元素在视口中的位置和可见性。
telemetry 模块
telemetry 模块是 Browser-Use 项目的辅助组件,负责收集和发送匿名使用数据,帮助开发者了解项目的使用情况和性能表现。 其主要功能包括:
匿名数据收集:收集用户的匿名使用数据,如代理运行情况、步骤执行、注册的功能等。
事件跟踪:定义和跟踪各种遥测事件,如代理启动、步骤执行、代理结束等。
数据发送:将收集的数据发送到 PostHog 分析平台。
用户隐私保护:提供禁用遥测功能的选项,尊重用户隐私。
用户标识管理:生成和管理匿名用户标识符,用于关联同一用户的数据。
执行流程时序分析
初始化阶段
初始化阶段主要包括以下步骤:
-
用户创建代理:用户提供任务描述、语言模型和浏览器实例,创建 Agent 对象
-
初始化消息管理器:Agent 初始化 MessageManager,设置系统提示和任务消息
-
初始化控制器:Agent 初始化 Controller,注册各种浏览器操作
-
记录遥测事件:Agent 通过 ProductTelemetry 记录代理启动事件
-
完成初始化:Agent 向用户返回初始化完成的信息
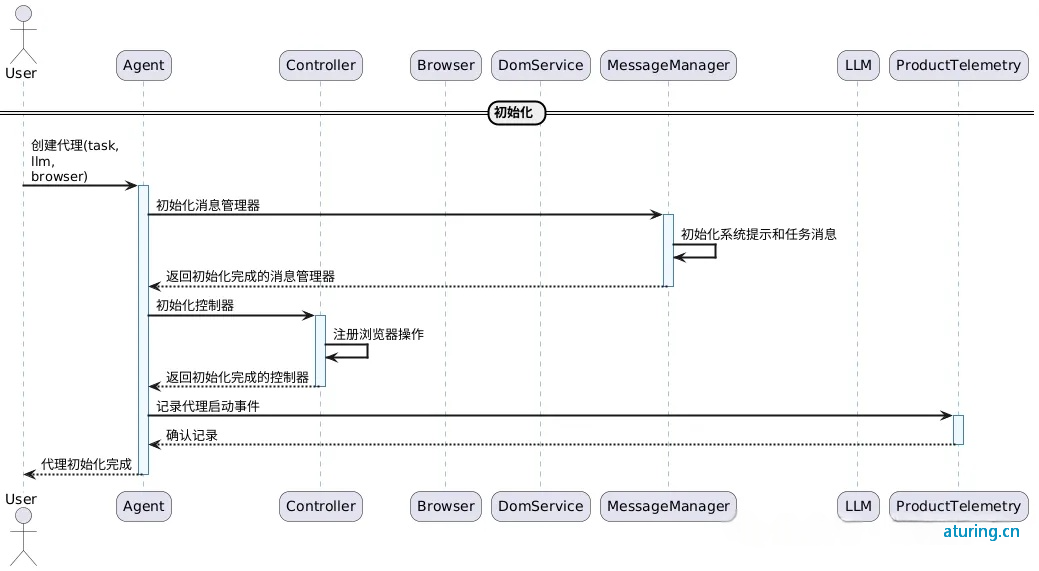
执行循环阶段
执行循环阶段是整个流程的核心,代理会重复执行以下步骤,直到任务完成或达到最大步骤数:
获取浏览器状态:
-
Agent 从 Browser 获取当前状态
-
Browser 通过 DomService 获取 DOM 元素和可点击元素
-
Browser 返回浏览器状态给 Agent
准备 LLM 输入:
-
Agent 将浏览器状态添加到 MessageManager
-
Agent 从 MessageManager 获取完整的消息列表
-
获取下一步操作:
-
Agent 将消息发送给 LLM
-
LLM 返回 AgentOutput,包含思考过程和要执行的动作
-
Agent 将模型输出添加到 MessageManager
执行动作:
-
Agent 通过 Controller 执行动作
-
Controller 根据动作类型调用 Browser 的不同方法:
-
导航操作:导航到指定 URL
-
点击操作:点击页面上的元素
-
输入操作:在元素中输入文本
-
完成操作:标记任务完成
-
Controller 返回 ActionResult 给 Agent
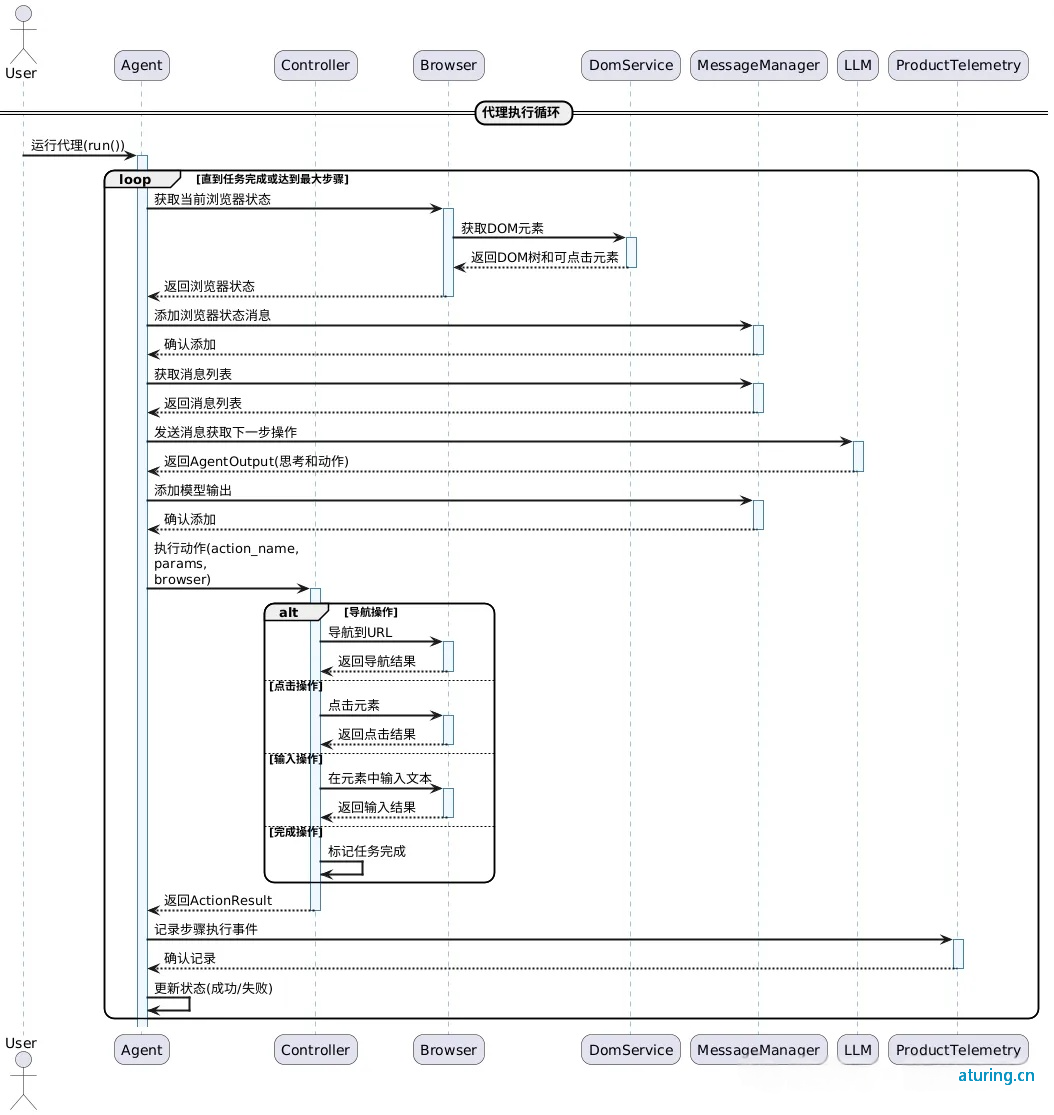
结束阶段
-
当任务完成或达到最大步骤数时,代理会执行以下步骤:
-
记录结束事件:Agent 通过 ProductTelemetry 记录代理结束事件。
-
返回历史记录:Agent 向用户返回 AgentHistoryList,包含所有步骤的详细信息。
-
可选生成 GIF:如果启用了 GIF 生成功能,Agent 会处理历史记录和截图,生成一个展示整个过程的 GIF 文件。
2、快速开始
环境配置
Browser-Use 推荐使用 uv 包管理器(Python >= 3.11):
# 创建项目环境
uv init
# 安装 Browser-Use
uv add browser-use
uv sync
# 安装 Chromium 浏览器
uvx browser-use install
配置 API 密钥
创建 .env 文件并添加 API 密钥:
# 推荐使用 ChatBrowserUse(新用户赠送 $10 免费额度)
# https://cloud.browser-use.com/analytics
BROWSER_USE_API_KEY=your-key
# 或使用其他 LLM 提供商
# OPENAI_API_KEY=your-key
# ANTHROPIC_API_KEY=your-key
# GOOGLE_API_KEY=your-key
基本示例
from browser_use import Agent, Browser, ChatBrowserUse
import asyncio
async def example():
# 初始化浏览器
browser = Browser(
headless=False, # 显示浏览器窗口
window_size={'width': 1280, 'height': 720}
)
# 初始化 LLM
llm = ChatBrowserUse()
# 创建 Agent
agent = Agent(
task="访问 GitHub 并找到 browser-use 项目的星标数量",
llm=llm,
browser=browser,
)
# 执行任务
history = await agent.run()
# 获取结果
print(f"任务完成: {history.final_result()}")
print(f"访问的 URL: {history.urls()}")
return history
if __name__ == "__main__":
asyncio.run(example())
3、核心组件详解
Agent(代理)
Agent 是 Browser-Use 的核心组件,负责任务理解、规划和执行。
关键参数配置
agent = Agent(
task="你的任务描述",
llm=ChatBrowserUse(),
browser=browser,
# 视觉能力配置
use_vision="auto", # "auto" | True | False
vision_detail_level="auto", # "low" | "high" | "auto"
# 行为控制
max_actions_per_step=4, # 每步最大操作数
max_failures=3, # 最大失败重试次数
use_thinking=True, # 启用推理过程
flash_mode=False, # 快速模式(跳过评估)
# 工具配置
tools=tools, # 自定义工具集
# 输出配置
output_model_schema=YourPydanticModel, # 结构化输出
generate_gif=True, # 生成操作 GIF
)
执行与结果获取
# 执行任务
history = await agent.run(max_steps=100)
# 分析结果
print(history.final_result()) # 最终结果
print(history.is_successful()) # 是否成功
print(history.urls()) # 访问的 URL 列表
print(history.action_names()) # 执行的操作列表
print(history.screenshots()) # 截图列表
print(history.errors()) # 错误列表
print(history.model_thoughts()) # AI 推理过程
Browser(浏览器)
Browser 组件管理浏览器实例和会话。
本地浏览器配置
使用本地Chrome浏览配置和用户数据,可避免二次登录
C:\Users\Administrator\AppData\Local\Google\Chrome\User Data
C:\Program Files\Google\Chrome\Application\chrome.exe
browser = Browser(
# 显示设置
headless=False,
window_size={'width': 1920, 'height': 1080},
viewport={'width': 1280, 'height': 720},
# 用户数据
user_data_dir=r'C:\Users\Administrator\AppData\Local\Google\Chrome\User Data', # 保留登录状态
profile_directory='Default',
# 网络配置
proxy=ProxySettings(
server='http://proxy:8080',
username='user',
password='pass'
),
# 域名限制
allowed_domains=['*.example.com', 'https://trusted.com'],
prohibited_domains=['*.malicious.com'],
# 控制优化
minimum_wait_page_load_time=0.25,
wait_for_network_idle_page_load_time=0.5,
wait_between_actions=0.5,
)
云端浏览器
# 使用 Browser-Use Cloud(推荐用于生产环境)
browser = Browser(
use_cloud=True, # 自动配置云端浏览器
cloud_profile_id='your-profile-id', # 使用特定配置
cloud_proxy_country_code='us', # 代理位置:us, uk, fr, jp 等
cloud_timeout=30, # 会话超时(分钟)
)
Tools(工具系统)
Browser-Use 提供丰富的内置工具,同时支持自定义扩展。
内置工具
导航与浏览器控制
-
search: 搜索查询(支持 DuckDuckGo、Google、Bing) -
navigate: 导航到指定 URL -
go_back: 返回上一页 -
wait: 等待指定秒数
页面交互
-
click: 点击元素 -
input: 输入文本 -
scroll: 滚动页面 -
send_keys: 发送特殊按键(Enter、Escape 等) -
upload_file: 上传文件
数据提取
-
extract: 使用 LLM 提取页面数据 -
screenshot: 请求截图
标签页管理
-
switch: 切换标签页 -
close: 关闭标签页
文件操作
-
write_file: 写入文件 -
read_file: 读取文件 -
replace_file: 替换文件内容
自定义工具
from browser_use import Tools, ActionResult, Browser
tools = Tools()
@tools.action(
description='向人类请求帮助',
allowed_domains=['*.example.com'] # 可选:限制域名
)
def ask_human(question: str, browser: Browser) -> ActionResult:
"""
自定义工具示例
参数:
question: 要询问的问题
browser: Browser 实例(可选,用于确定性操作)
"""
answer = input(f'{question} > ')
return ActionResult(
extracted_content=f'用户回答:{answer}',
long_term_memory='记住这个答案用于后续任务',
success=True
)
# 获取 2FA 验证码示例
@tools.action('从认证器应用获取 2FA 验证码')
async def get_2fa_code() -> str:
# 实现你的 2FA 逻辑
code = get_code_from_authenticator()
return code
# 使用自定义工具
agent = Agent(
task='登录需要 2FA 的网站',
llm=llm,
browser=browser,
tools=tools
)
4、示例
表单自动填写
"""
示例2: 表单自动填写
演示如何自动填写网页表单
"""
from browser_use import Agent, Browser, ChatBrowserUse
from dotenv import load_dotenv
import asyncio
load_dotenv()
async def fill_form_example():
"""自动填写表单示例"""
browser = Browser(
headless=False,
window_size={'width': 1280, 'height': 720}
)
# 定义表单数据
form_data = {
'name': '张三',
'email': 'zhangsan@example.com',
'message': '这是一条测试消息,由 Browser-Use 自动填写。'
}
agent = Agent(
task=f"""
访问 https://www.scrapethissite.com/pages/forms/
这是一个练习网站,请浏览页面内容并提取前5个国家的名称和获胜次数。
使用 extract 工具提取数据,格式如下:
- 国家名称
- 获胜年份
- 获胜次数
""",
llm=ChatBrowserUse(),
browser=browser,
max_actions_per_step=6 # 允许一次填写多个字段
)
print("开始执行表单填写任务...")
history = await agent.run()
print("\n" + "="*50)
if history.is_successful():
print(" 表单填写成功!")
print(f" 提取结果:\n{history.final_result()}")
else:
print("❌ 任务失败")
print(f"错误信息: {history.errors()}")
print("="*50)
return history
if __name__ == "__main__":
asyncio.run(fill_form_example())
数据采集与提取
"""
示例3: 数据采集与提取
使用结构化输出提取网页数据
"""
from browser_use import Agent, Browser, ChatBrowserUse
from pydantic import BaseModel
from typing import List
from dotenv import load_dotenv
import asyncio
import json
load_dotenv()
# 定义数据结构
class Quote(BaseModel):
"""引用数据模型"""
text: str
author: str
tags: List[str]
class QuoteList(BaseModel):
"""引用列表模型"""
quotes: List[Quote]
async def scrape_quotes_example():
"""采集网站引用信息"""
browser = Browser(
headless=False,
window_size={'width': 1280, 'height': 720}
)
agent = Agent(
task="""
访问 https://quotes.toscrape.com/
提取前 5 条引用的信息:
- 引用文本 (text)
- 作者 (author)
- 标签列表 (tags)
使用 extract 工具提取数据。
""",
llm=ChatBrowserUse(),
browser=browser,
output_model_schema=QuoteList # 结构化输出
)
print("???? 开始数据采集任务...")
history = await agent.run()
print("\n" + "="*50)
if history.is_successful():
print("✅ 数据采集成功!")
# 获取结构化数据
quotes_data = history.structured_output
if quotes_data and hasattr(quotes_data, 'quotes'):
print(f"\n???? 采集到 {len(quotes_data.quotes)} 条引用:\n")
for i, quote in enumerate(quotes_data.quotes, 1):
print(f"{i}. \"{quote.text}\"")
print(f" 作者: {quote.author}")
print(f" 标签: {', '.join(quote.tags)}")
print()
# 保存到文件
output_file = "demo-examples/output/quotes.json"
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(
[q.model_dump() for q in quotes_data.quotes],
f,
ensure_ascii=False,
indent=2
)
print(f"???? 数据已保存到: {output_file}")
else:
print(f"???? 提取结果: {history.final_result()}")
else:
print("❌ 采集失败")
print(f"错误: {history.errors()}")
print("="*50)
return history
if __name__ == "__main__":
# 确保输出目录存在
import os
os.makedirs("demo-examples/output", exist_ok=True)
asyncio.run(scrape_quotes_example())
自动化测试
"""
示例4: 自动化测试
演示如何使用 Browser-Use 进行网站功能测试
注意:在PyCharm中运行时,请右键选择 "Run '04_automated_testing'"
而不是 "Run 'pytest in 04_automated_testing.py'"
"""
import sys
import os
# 添加项目路径
sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
from browser_use import Agent, Browser, ChatBrowserUse
from dotenv import load_dotenv
import asyncio
load_dotenv()
async def website_example():
"""测试网站功能"""
browser = Browser(
headless=False,
window_size={'width': 1280, 'height': 720},
# 可选:录制视频
# record_video_dir='./demo-examples/output/videos'
)
agent = Agent(
task="""
访问 https://quotes.toscrape.com/ 并执行以下测试:
1. 验证页面标题是否包含 "Quotes"
2. 检查页面是否显示引用内容
3. 点击第一个作者的链接
4. 验证是否成功跳转到作者详情页
5. 使用 extract 工具提取作者的名字和出生日期
6. 返回首页
7. 验证是否成功返回
对于每个步骤,请明确说明测试是否通过。
""",
llm=ChatBrowserUse(),
browser=browser,
generate_gif=True # 生成操作 GIF
)
print("???? 开始自动化测试...")
history = await agent.run()
print("\n" + "="*50)
print("???? 测试结果")
print("="*50)
if history.is_successful():
print("✅ 所有测试通过!")
print(f"\n???? 测试详情:\n{history.final_result()}")
print(f"\n???? 访问的页面: {history.urls()}")
print(f"???? 截图数量: {len(history.screenshots())}")
# 显示 GIF 路径(如果生成)
if hasattr(browser, 'gif_path'):
print(f"???? 操作 GIF: {browser.gif_path}")
else:
print("❌ 测试失败")
errors = [e for e in history.errors() if e]
if errors:
print("\n错误列表:")
for i, error in enumerate(errors, 1):
print(f"{i}. {error}")
print("="*50)
print(f"⏱️ 总耗时: {history.total_duration_seconds():.2f} 秒")
return history
if __name__ == "__main__":
# 确保输出目录存在
import os
os.makedirs("demo-examples/output", exist_ok=True)
asyncio.run(website_example())
购物
import asyncio
import os
import sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
from dotenv import load_dotenv
load_dotenv()
from browser_use import Agent, Browser, ChatBrowserUse
# ============ 配置说明 ============
# 方案1:使用现有Chrome配置(保留登录状态)
# 优点:可以使用已登录的淘宝账号
# 缺点:需要先完全关闭Chrome浏览器
#
# 方案2:使用临时配置文件
# 优点:不需要关闭Chrome,可以直接运行
# 缺点:需要重新登录淘宝
# 方案1:使用现有Chrome配置(需要先完全关闭Chrome!)
browser = Browser(
headless=False,
executable_path=r'C:\Program Files\Google\Chrome\Application\chrome.exe',
user_data_dir=r'C:\Users\Administrator\AppData\Local\Google\Chrome\User Data',
profile_directory='Default',
keep_alive=True,
)
# 方案2:使用临时配置文件(不需要关闭Chrome)
# browser = Browser(
# headless=False,
# executable_path=r'C:\Program Files\Google\Chrome\Application\chrome.exe',
# keep_alive=True,
# )
task = """
### 任务:在淘宝购买钢笔
**目标:**
访问淘宝网(https://www.taobao.com),搜索并购买一支钢笔。
**步骤:**
1. 打开淘宝网站 https://www.taobao.com
2. 在搜索框中输入"钢笔"
3. 浏览搜索结果,选择一支价格合适、评价较好的钢笔(建议价格在50-200元之间)
4. 查看商品详情,包括价格、评价、销量等信息
5. 将商品加入购物车
6. 进入购物车确认商品信息
7. 输出购买的商品信息,包括:
- 商品名称
- 价格
- 店铺名称
**注意事项:**
- 如果需要登录,请等待手动登录完成
- 选择信誉好、评价高的店铺
- 提交订单后不要付款,让我自己决定是否付款
"""
agent = Agent(
task=task,
browser=browser,
llm=ChatBrowserUse(), # 使用推荐的Browser Use专用模型
)
async def main():
await agent.run()
input('Press Enter to close the browser...')
if __name__ == '__main__':
asyncio.run(main())
5、其它
提示词优化
具体明确的任务描述
# ✅ 推荐
task = """
1. 访问 https://quotes.toscrape.com/
2. 使用 extract 工具提取前 3 条引用及其作者
3. 使用 write_file 工具保存到 quotes.csv
4. 对第一条引用进行 Google 搜索,找出写作时间
"""
# ❌ 不推荐
task = "去网上赚钱"
直接引用工具名称
task = """
如果提交按钮无法点击:
1. 使用 send_keys 工具发送 "Tab Tab Enter" 进行导航和激活
2. 或使用 send_keys 发送 "ArrowDown ArrowDown Enter" 提交表单
"""
认证处理
使用真实浏览器配置
browser = Browser(
executable_path='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome',
user_data_dir='~/Library/Application Support/Google/Chrome',
profile_directory='Default', # 使用已登录的配置
)
同步本地 Cookie 到云端
# 同步认证信息到云端浏览器
export BROWSER_USE_API_KEY=your_key
curl -fsSL https://browser-use.com/profile.sh | sh
性能优化
agent = Agent(
task="你的任务",
llm=ChatBrowserUse(),
browser=browser,
# 快速模式(跳过评估和推理)
flash_mode=True,
# 限制历史记录
max_history_items=10,
# 使用小型模型进行页面提取
page_extraction_llm=ChatBrowserUse() # 或其他快速模型
)
错误处理
async def robust_task():
browser = Browser()
agent = Agent(
task="""
访问 openai.com 查找 CEO 信息
如果导航失败(反爬虫保护):
- 使用 search 工具在 Google 搜索 CEO 信息
如果页面超时:
- 使用 go_back 返回并尝试其他方法
""",
llm=ChatBrowserUse(),
browser=browser,
max_failures=5 # 增加重试次数
)
history = await agent.run()
if not history.is_successful():
print("任务失败,错误信息:")
for error in history.errors():
if error:
print(f"- {error}")
asyncio.run(robust_task())
模型选择
-
ChatBrowserUse(推荐):专为浏览器自动化优化,速度快 3-5 倍,成本低
-
GPT-4.1-mini:通用任务,性价比高
-
Claude Sonnet 4.0:复杂推理任务
-
Gemini Flash:快速响应场景
-
本地模型(Ollama):隐私敏感场景
应用场景
-
网页截图:自动化批量截图,用于网站内容监控、视觉测试、内容存档等。
-
数据抓取(Web Scraping):智能数据提取,用于市场调研、竞争情报、价格监控、新闻聚合等。
-
自动化测试:AI 驱动的测试用例生成和自动化测试脚本编写,用于 Web 应用的回归测试、冒烟测试、UI 测试等。
-
内容生成:自动化生成各种类型的网页内容,例如自动填写表单、生成产品描述、撰写评论等,用于内容营销、SEO 优化、广告创意生成等。
-
AI 代理与浏览器交互:使用自然语言指令控制浏览器行为,用于智能助手、自动化工作流、RPA(机器人流程自动化)等。
-
在线订票: 自动化查找和预订机票、酒店等。
-
求职申请: 自动化填写求职申请表。
-
智能客服:结合 LLM 和浏览器自动化,可以实现智能客服,自动回答用户的问题,并引导用户完成操作。
-
自动化金融分析:自动抓取和分析金融数据,生成投资报告和风险评估。
-
智能招聘:自动抓取招聘信息,筛选候选人,并进行初步面试。
-
自动化内容审核:自动审核网页内容,识别违规信息,并进行处理。
-
智能家居控制:通过浏览器自动化控制智能家居设备,例如灯光、空调、电视等。
-
游戏自动化:通过浏览器自动化玩网页游戏,例如自动打怪、自动升级等。
文档
-
官方文档: https://docs.browser-use.com
-
GitHub 仓库: https://github.com/browser-use/browser-use
-
云服务: https://cloud.browser-use.com
-
示例代码: https://github.com/browser-use/browser-use/tree/main/examples
- 上一篇: Chromedp原理及使用
- 下一篇: openclaw介绍及环境搭建
如果您喜欢我的文章,请点击下面按钮随意打赏,您的支持是我最大的动力。
最新评论